東北大学タフ・サイバーフィジカルAI研究センター
特任教授 田所諭氏
第2回
空間エージェント網が切り拓く未来
(1)困難環境下のインテリジェンスの検討
遠隔操縦ロボットのインテリジェンスを実現するループ
次に、このようなインテリジェンスがどのようにして実現されるのかを考えてみます。
Quinceを開発したNEDO(国際研究開発法人・新エネルギー・産業技術総合開発機構)の戦略的先端ロボット要素技術開発プロジェクトでは、地下街の中を走り回って内部を調べるというミッションを検討していました。このような、一見単純なインテリジェンスをどのようにして実現するかを考えたものが以下の図になります。
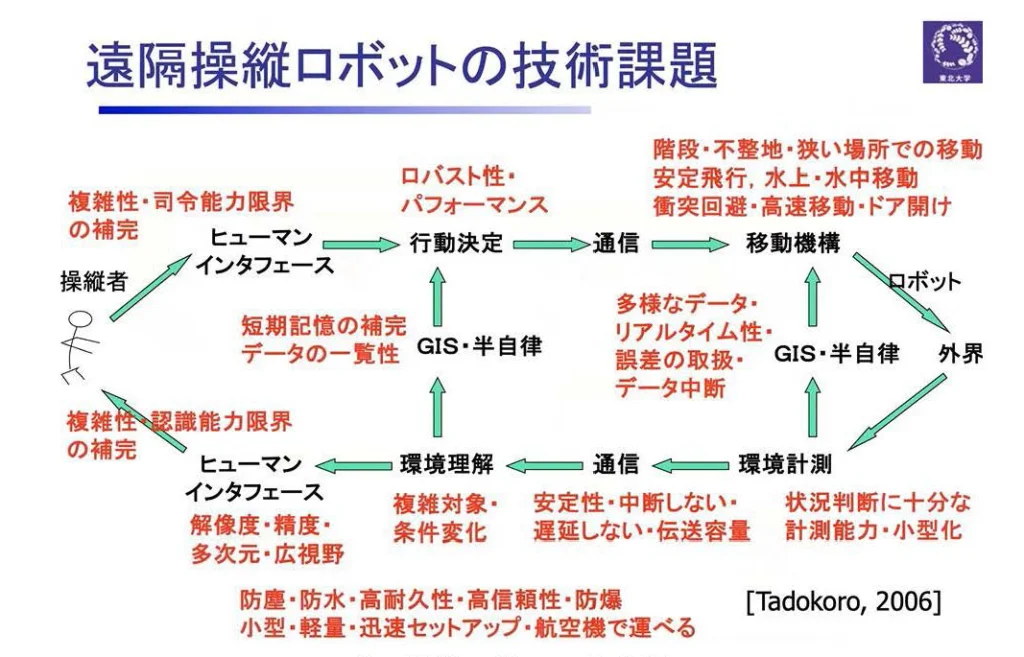
上図は、ロボットの内部と外部のデータフローを表したものです。
右側にロボットがいます。ロボットはボディを持っていて、移動機能とセンシング機能を持っており、外界に対して働きかけを行い、また、外界の変化を検出します。それを基にしてロボットの作業が計画されると、これが一つの自律機能になるわけです。
このような自律的に動けるロボットが、通信でオペレータ側と繋がれることになります。ここでは、オペレータ側で行動決定をしてロボットに指令する。あるいは、ロボットが収集したセンシングデータをオペレータが理解する。そういうインテリジェントな処理をリモートで行うということが想定されています。
リモートで行われた環境理解の結果がヒューマン・インターフェースを介して操縦者に送られ、操縦者の意図はヒューマン・インターフェースを介してロボットの行動決定に反映される。このような何重にもわたるループが動くことによってインテリジェンスができる。そのような整理をしてQuinceの研究開発が行われました。
災害対応ロボットの機能構成と困難環境下での技術課題
その後東日本大震災の後で、COCN(Council on Competitive-Nippon 産業競争力懇話会)において60社ほどの企業、政府、研究者の方々に集まっていただき、困難条件下での技術課題は何かを議論しました。
例えば移動の機能一つとってみても、凹凸段差、地盤崩壊、障害物、強風、耐久性等々、様々な事柄が重要な要因になってきます。作業性能、センシング性能、それに加えて、無線性能、そして遠隔操作と自律知能。困難条件下で必要となる要素をまとめました。
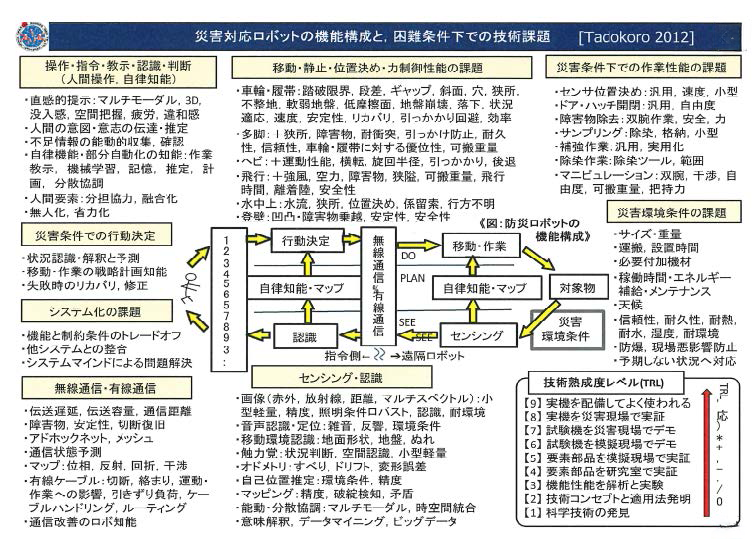
この時点での技術課題を挙げたのですが、実はもっともっとインテリジェントにしていかなければならない、というのが現実の要求であります。
困難環境におけるロボットのインテリジェンスのレベル化
困難環境におけるロボットのインテリジェンスというものを整理すると、以下のようなものになります。
- Full Autonomy ロボットが自分で考えて行動
- Adjusted Autonomy 人間の介入レベルを状況に応じて調整
- Supervised Autonomy 人間の管理下で自律行動
- Shared Autonomy 自律機能に人間が介入
- Guided Autonomy 自律機能によるガイドを受けながら遠隔操作
- Assisted Autonomy 自律機能に支援されながら遠隔操作
- Manual Teleoperation 人間が遠隔操作
1で示したFul Autonomyとは、ロボットが自分で考えて自分で行動できるということです。つまり、ロボットが人間と全く同じように行動ができるのです。熟練作業者が現場に行って何をするかを自分で判断して自分で修理を行ったり、点検をしたりする。そういうことを全部できるのがFull Autonomyになります。
それに対して、人間の管理下で実行動を行うのは、3.Supervised Autonomy、あるいは、自律機能に人間が介入する4.Shared Autonomyのレベルになります。
そのレベルを調整できるようにしたものが2.Adjusted Autonomyです。ロボットが自動的に行えるものと人間が介入するものを最適に組みあわせてうまく使い分けながら自律的な機能を果たしていくレベルです。
現場で点検するロボットに対して、どんなことを点検してほしいという指示を人間が与えて、ロボットが現場を動き回って指示事項を調べてくるというのは、典型的な3.Supervised Autonomyであり、あるいは場合によっては4.Shared Autonomyのレベルであるわけです。
5.Guided Autonomyは、自律機能によるガイドを受けながら人間がロボットを遠隔操作するというものです。右に動けと指示するとロボットは自分で動いてくれます。そこは自律なのですが、人間がテレオペレーションしています。
6. Assisted Autonomyは人間がテレオペレーションをするけれども、ある時にある事態に至ると自律機能がはたらく。例えば転倒しそうだから危ないよと教えてくれる。そういった支援があるのが6のAssisted Autonomyになります。
まずはインテリジェンスのレベルを考えていく必要があります。自律して動き回ることだけを絶対視して考えるべきではありません。ロボットの部分的な機能である認識系、移動系、マニピュレーション、作業系、知能系、協調など、様々な部分で自律的に行えるはたらきが沢山あります。
認識系では、ロボットがセンサー・データを生で送ってくるだけというレベルから、データから解釈してマッピングしたり、理解をしたりして、そこで何が起きているかまで分かるというレベル、要するに、得られた生データと現象との間の対応関係がどうなっているかを考えてくれるレベルになれば、自律性が高く有用です。
運動も同じです。モーターをオン、オフする。スピードを変える。そういうところから始まって、それをさらに上位レベルに上げて、ナビゲーションをしたり、移動の行動計画をつくれたりするレベルまで高めていきます。ロボットに対して「点検してこい」と指示しただけで、このような運動制御が自律的に行われるのであれば、そのロボットはしっかりと働いていると評価していいでしょう。
自律できる機能が全部整わなくても、認識系の能力を果たしてくれて、それが有意義であれば、ぜひその能力を向上させていくべきです。他にも、協調し合う複数台のロボット、IoT、人間とのやり取りができるロボット等いろいろな自律的なはたらきをするロボットがあります。従来の制御機器等とも協力をしながら自律機能を高めていく。そういうアプローチが求められています。
(2)トラディショナルなモデルの検討
①4D/RCSアーキテクチャのアプローチ
●アルバス氏による4D/RCSアーキテクチュア その1 初期版
ロボットのインテリジェンスをどう整理すればよいのか。トラディショナルには下図の構造がスタンダードなモデルです。
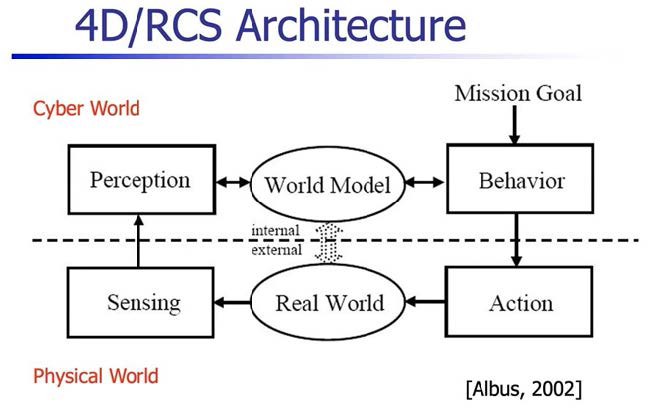
上図はアルバス氏が2002年に発表した、4D/RCS(Four Dimensional Real-time Control System)というアーキテクチャです。点線より上部がサイバーの世界で、下部がフィジカルの世界です。ワールド・モデルとリアル・ワールドの楕円形が中央の上下に配置されています。
様々な形でリアル・ワールドのセンシングがフィジカル・ワールドで行われて、その情報がサイバー・ワールドに伝えられて、それがパーセプションによってシンボライズされて、ワールド・モデルを更新していくというものです。
ロボットには、何をやるべきかというミッションのゴールが与えられていて、このワールド・モデルを使うことによってビヘイビアを生成していく。このビヘイビアをもとにフィジカル空間でミッションに対するアクションを起こし、それがリアル・ワールドにおいて実際に移動したり調査したりといったロボットの行動につながっていく。
サイバー・ワールドとフィジカル・ワールドとをうまく同期させながら、サイバー・ワールドの中でインテリジェントなことを計画し、フィジカル・ワールドでそれを実現していくというのが、この当時の基本的な考え方でした。
●4D/RCSアーキテクチュア その2 デジタルツインに展開
4D/RCSアーキテクチュアは、米国商務省のNIST(National Institute of Standards and Technology)という機関の研究成果であり、軍事目的の無人車両システムのための参照モデルです。
前掲の初期版の図をもう少し詳しく書いたものが下図です。
サイバー空間の[センサリー・プロセッシング]、[ワールド・モデリング/バリュー・ジャッジメント]、[ビヘイビア・ジェネレーション]。フィジカル・ワールドの[センサー]、[ワールド]、[アクチュエーター]。この図は知能と肉体をツインにして動かしていくデジタルツインのまさに典型的なモデルであります。
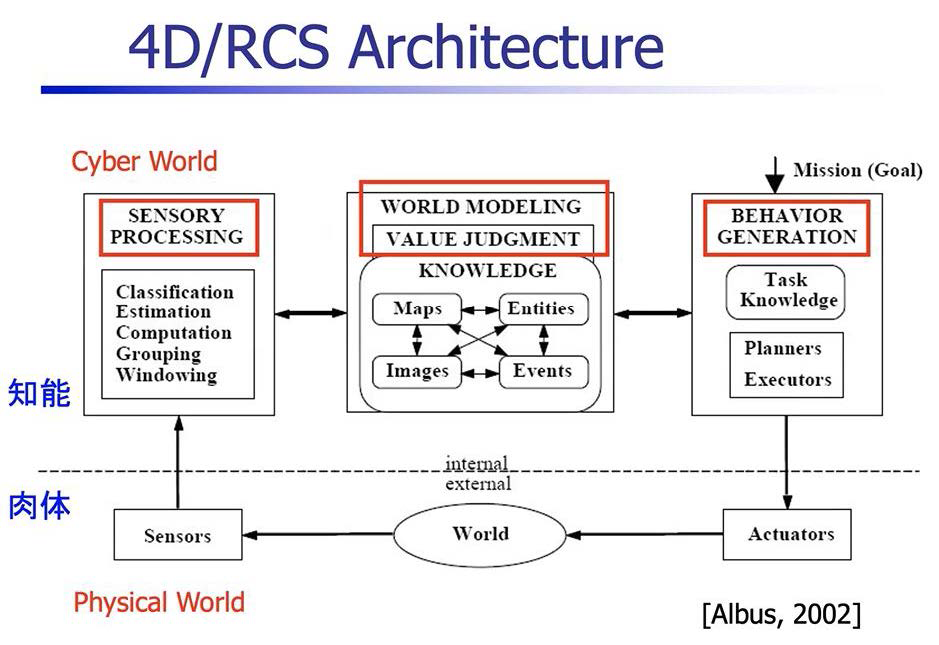
もちろんこんな風に単純に行く筈はありませんので、それはアルバス氏もよくわかっています。
●4D/RCSアーキテクチュア その3 知能の階層化
そこでこれを現実の世界でどんな風に展開していくかを、次頁の図のように知能の部分を階層的に描いています。
フィジカル・ワールドの[センサリー・プロセッシング]⇔[ワールド・モデリング/バリュー・ジャッジメント]⇔[ビヘイビア・ジェネレーション(行動生成)]の相互作用が、フィジカル・ワールドの[センサー]⇔[ワールド]⇔[アクチュエーター]にいたるまでを、抽象度、解像度、距離、時間に応じて5階層の知能のはたらきに展開していきます。
ビヘイビア・ジェネレーションの欄を見ると5階層はこの図では上から、
・Section(分隊)
・Vehicle(車両)
・Subsystem
・Primitive
・Servo
となっており、それぞれの階層で[センサリー・プロセッシング]からのインプットによって更新された[ワールド・モデリング]からシミュレーションして[ビヘイビア・ジェネレーション(行動生成)]―知能を発揮した計画策定-がなされます。
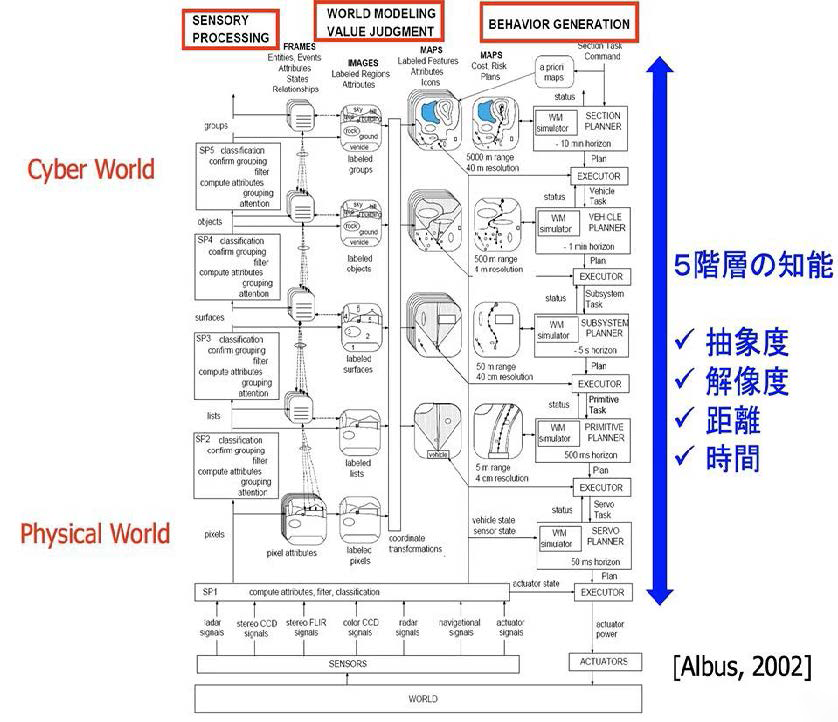
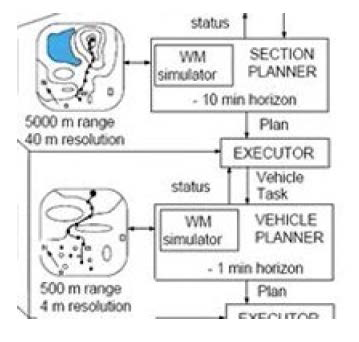
この流れをこの抜粋した図に即して丁寧に見てみましょう。最上位の階層では、タスクの指令を受けたSection Plannerは、「5000mの範囲」「40m解像度」の マップを参照し、10分先までの行動計画(10 min horizon)を策定。Vehicle(車両)のプランをアウトプットし、それがExecutor(タスク変換モジュール)にインプットされるとExecutorは、Vehicleのタスクをアウトプットし、Vehicleにタスクを指令します。
Vehicle Plannerはそのタスクに基づき、Executor(タスク変換モジュール)に「500mの範囲」「4m解像度」のマップを参照し、1分先までの行動計画(1 min horizon)の行動計画を策定し、Subsystemのプランをアウトプットします。
Vehicle Plannerにそのタスクを指令します。
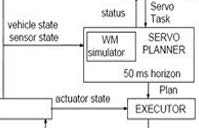
最下位の階層のサーボでは、フィジカル空間において、Servo Plannerに、実際の車両の状態、センサーの状態を入力し、0.05秒(50ミリ秒)先までの計画を立てActuatorをリアルタイム制御するためのプランをExecutorに送ります。Executorは、そのプランのもとActuatorの状態の情報を入力し、アクチュエーターに動作レベルの指令を送ります。
以上のように、上位概念の意思決定からプリミティブなデータ・レベルへ、さらにはボディのモーションレベルに至るまでそれらを階層的に分けることによって知能によるロボット制御を統一的に考えていこうというのが、「アルバス氏による4D/RCSアーキテクチュア その3 知能の階層化」のコンセプトです。
●4D/RCSアーキテクチュア その4 取扱い範囲の階層化
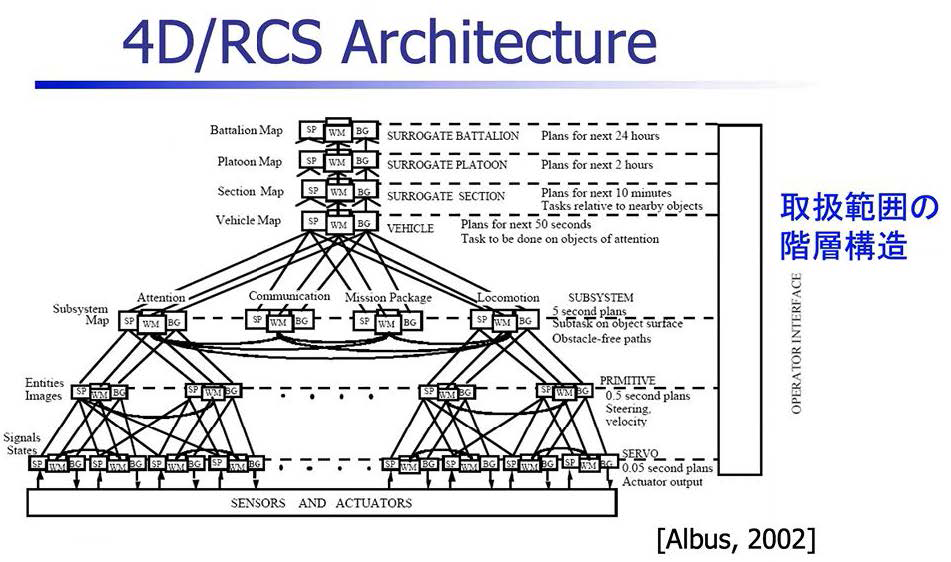
同じような階層の考え方で、取り扱う範囲を階層構造にしたものが次の図です。
サーボ・レベルからプリミティブ・レベル、サブシステムのレベル、それから、Vehicle(車両)、Section(分隊)、プラトーン(小隊)、カンパニー(中隊)、バタリアン(大隊)のレベルまで取り扱う範囲を狭いところから広いところまで階層構造で示しています。
尚、図中のボックスの中にSP、WM、BGという文字が記されています。これはそれぞれ[SP=センサリー・プロセッシング]、[WM=ワールド・モデリング]、[BG=ビヘイビア・ジェネレーション]という略語です。
●4D/RCSアーキテクチュア その5 構成要素の階層化
アルバス氏は構成要素の階層構造も考えています。
以下のように、サーボ・レベルから、もっと大きなVehicleのレベル、あるいはカンパニーのレベル、こういうふうなレベルに分けて階層構造を作ることによって、整理して組み立てていこうという考え方です。
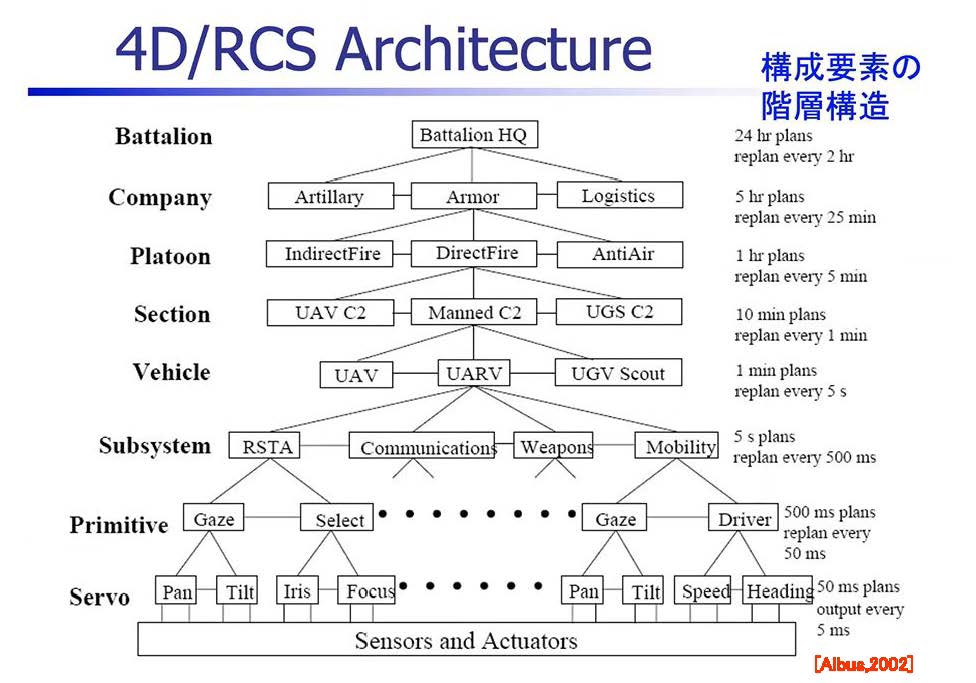
それでは上から辿って見てみましょう。
●Battalion(大隊レベル)
Battalion HQ(大隊本部)
→ 24時間先の計画(再計画周期:2時間ごと)
●Company(中隊レベル)
Artillery(砲兵部隊)
Armor(装甲部隊)
Logistics(兵站部隊)
→ 5時間先の計画(再計画周期:25分ごと)
●Platoon(小隊レベル)
Indirect Fire(間接射撃)
Direct Fire(直接射撃)
AntiAir(対空防御)
→ 1時間先の計画(再計画周期:5分ごと)
各小隊の戦術的な動作を決定し、より具体的な指示を出す。
●Section(分隊レベル)
UAV C2(無人航空機指揮)
Manned C2(有人指揮)
UGS C2(地上センサー指揮)
●Vehicle(車両レベル)
UAV(無人航空機)
UARV(無人自律車両)
UGV Scout(無人地上偵察車両)
→ 1分先の計画(再計画周期:5秒ごと)
●Subsystem(サブシステムレベル)
RSTA(偵察・監視・捕捉)
Communications(通信)
Weapons(武器システム)
Mobility(機動性・移動)
→ 5秒先の計画(再計画周期:500ミリ秒ごと)
●Primitive(原始的計画レベル)
Gaze(視線制御)
Select(選択)
Driver(運転制御)
→ 500ミリ秒先の計画(再計画周期:50ミリ秒ごと)
●Servo(サーボ制御レベル)
Pan(パン:左右の回転)
Tilt(チルト:上下の回転)
Iris(アイリス:カメラの絞り)
Focus(フォーカス:焦点調整)
Speed(速度制御)
Heading(方位制御)
→ 50ミリ秒先の計画(出力周期:5ミリ秒ごと)
この構成要素の階層構造をご覧になってわかる通り、4D/RCS(Four Dimensional Real-time Control System)は、極めて中央集権的であり、階層ごとにどんどんタスクを細分化していくアプローチです。Battalion (大隊)からの指令が各層でインプットとアウトプットを繰り返し末端のServo レベルまでくるとカメラの上下、左右の動き、フォーカスまで指示する体系になっています。
このように中央集権的に細部までタスクを割り当てていく指令体系で果たして環境変化や不測事態にシステムが対応できるのか。私たちは当初から疑問を抱いておりましたが、一応これがトラディショナルなモデルですのでご紹介いたしました。
②RRIのロボットシステム
もう一つトラディショナルなモデルを紹介します。
それは下図のようなロボットの典型的な知能構造です。これはRRI(ロボット革命・産業IoTイニシアティブ協議会)が作成したロボット・セキュリティ・ガイドラインの中に出てくる図です。ロボットのコンポーネントは確かにこのようにできあがっているのです。
ロボットは1台ではなく複数台存在し、それがローカル・ネットワークとしてネットワークにつながっている。ネットワーク上にはクラウドがあり、クラウドで処理が行われる。クラウドでは上位レベルの運用の処理がなされてロボットのローカル・ネットワークとの通信が行われる。ローカル・ネットワーク上で下位レベルの細かい処理が行われて、各ロボットにそれを指令し、
また、各ロボットがセンシングしたデータがローカル・ネットワークを通じてクラウドにあげられる。そういった構成になっています。
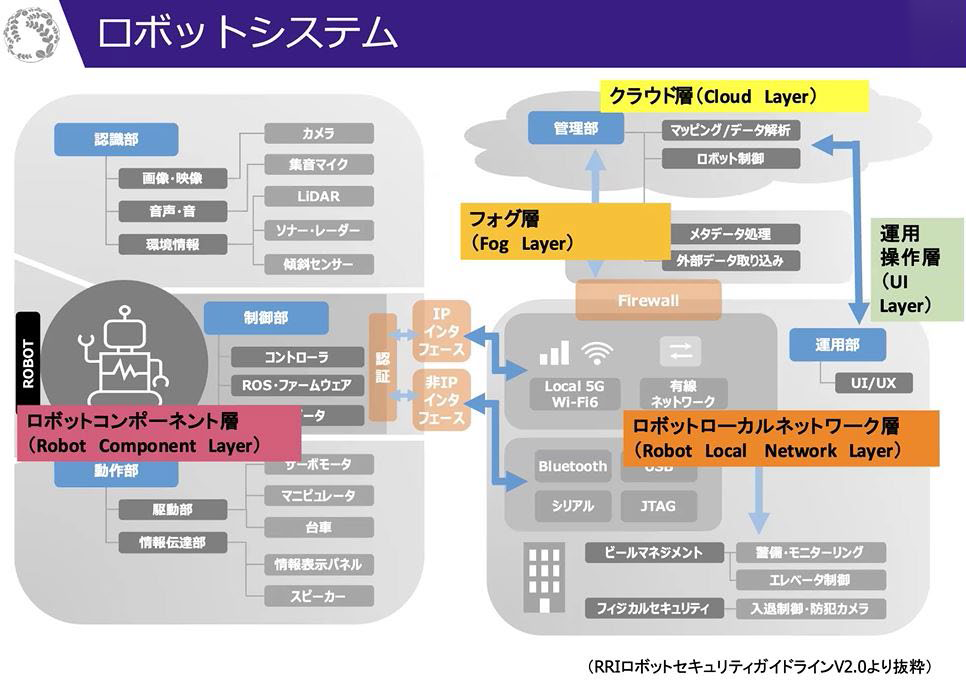
私がこれまでレスキュー・ロボットの技術課題とその困難さを散々語りましたので、今、紹介したトラディショナルなモデルで本当に課題解決が可能なのかという違和感を持つ方もおられるかもしれません。ですからここからは違う話をしたいと思います。
(3)空間エージェント網で展開するフィジカル・インテリジェンス
FDnetの発想:つながった状態がインテリジェンスになっていく
下の図はFlat Distributed Network アーキテクチャ(以下FDnet) です。日本語では「水平分散アーキテクチャ」と称します。2003年、神戸大学時代に徳田献一氏(現職は農研機構上級研究員)と私がディスカッションをして作成した概念図です。Albus氏の4D/RCSアーキテクチュアが2002年ですのでほぼ同時代のものです。
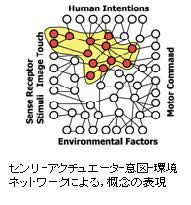
このFDnetは、センサー、アクチュエーター、意図、環境という4つのアイテムで構成されています。
これは、言語表現の違いはあれども、4D/RCSアーキテクチュアを構成するファクターとほぼ同じであると考えていいでしょう。この図に階層構造を組み入れると複雑なものができ上がるでしょうが、私たちは単純化して一層で描いてこのような概念を構築しました。
続けて下の「スキルの移転」の図を見てください。
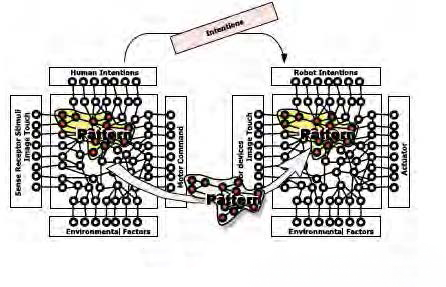
ネットワーク・コードで結んで、そのネットワークの発火している部分を意図だと捉えます。そうすると、図の左の意図のパターンを矢印のように右へ持っていけばスキルの移転ができるのではないか。当時はそんなことを考えていました。この考え方は、ニューラル・ネットワークやディープ・ラーニングなどが盛んになった今の時代では受け入れられやすいものだと思います。
しかし結局、構造というものをどのようにつくっていくかという観点からは、4D/RCSアーキテクチュアの階層の考え方とあまり差がないのです。では何がポイントなのか。
センサー、アクチュエーター、人間の意図、あるいは環境条件。要するに、それらの相互の関係性をどう構築していくのか、それらをどのようにしてロジックで結んでいくのかが勘所です。それらが繋がった状態が結局はインテリジェンスになっていくのです。
このネットワークにおいては、ロボットが単体であるか、複数であるかは関係ありません。ボディがどこにあるか、その機能がどこにあるか、そういうことはどうでもいいのです。要するにそれが繋がっていて、そこに機能があれば、その機能が地球の反対側で発現されようが問題ではありません。
ネットワークを構成しているものがロボットであるか、IoTであるか、あるいは単にカメラであるか、そんなことはあまり関係がなく、家電であっても構わないし、人間であるかどうかさえも関係ありません。
ネットワーク全体で、その情報が集められるか否か、集められた情報を活用してタフな世界でどのようにしてインテリジェントな機能を発現させることができるか。それが本質的に重要なポイントになります。
防災のデジタルツイン:サイバー空間のエージェントをフィジカル空間につなぐ
下図はその昔、ロボカップ・レスキュー・コンペティションを立ち上げる際に、知能の構造を考えてみたものです。
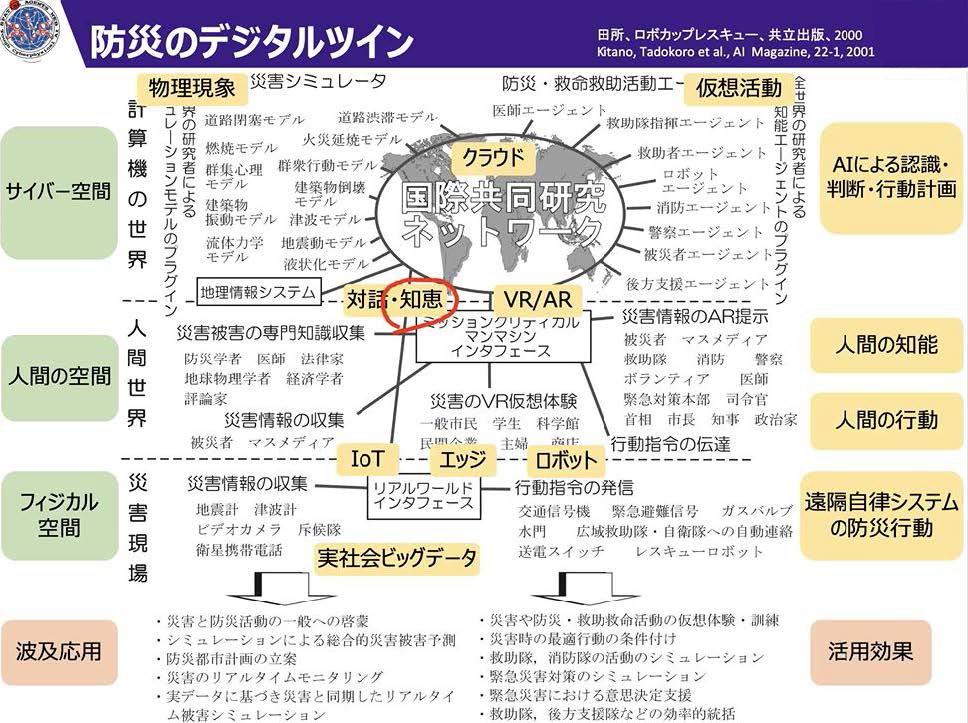
サイバー空間にシミュレータを置きました。サイバー空間でエージェント(人間の代理として働くAI)が活動して、どんな活動ができると災害被害を最小限に食い止めることができるかというシミュレーションがこのモデルの基本的な役割です。ここまではサイバー空間の話であります。
これをフィジカル空間と繋ぎますとデジタルツインになって、フィジカル空間で情報を収集することもできますし、フィジカル空間をコントロールすることもできます。
また、人間と繋ぐことによって人間に情報を伝えたり、あるいは訓練をやったり、災害の専門知識を吸収することも可能になります。
サイバー空間の中で、エージェントが持っている知能。あるいはこのモデル自体が持っている理解能力。それらが一つの知能(インテリジェンス)であります。また、フィジカル空間でどのような効果をもたらすことができるのか。あるいはどのようなセンシングできるのか。それらも一つの知能であります。はたまた、人間とどう協力できるか、人間の知能をどう活用できるかというところも、非常に重要な知能であります。
これらを融合させることでいかにして知恵として活用していくかが重要です。そういう意味で、20年以上前に徳田氏と共に発想しつくり上げたFlat-Distributed Network アーキテクチャ (FDnet)は本質をとらえたモデルだったのではないかと確信しています。
フィジカル空間に様々なインテリジェント機能が存在します。これらが連携して単独の知能を超えて集団としての知能ができ上がります。その集団知能をタフにいろいろな仕事ができるように構築していく。イレギュラーな事態にも適切な判断と行動ができるように知恵として鍛え上げていく。フィジカル・インテリジェンスはそういう開発の積み重ねの先に実現していきます。
災害の環境下でユーザーが求めるのは熟練者以上に優れた判断と行動
次に、ユーザー側のことを考えてみます。
ユーザーがロボットに何を求めているか。それは災害の環境下で熟練者以上に優れた判断、行動ができることです。これが実現できないとユーザーがロボットを採用することが難しい。なぜか。災害現場ではロボットと通信が切断される事態が想定されます。その際に、ロボットが自律機能を発揮して一定水準以上の高度な判断で動けないと作業が進まないからです。
「このパイプを切ってもいいんですか?」
そういう問いに解を出すのは簡単ではありません。そのプラントで何が起きているかを踏まえた上で、化学的な反応メカニズムを分かっていないと判断できないのです。一方、それを外から人間が指示しないといけないとなると、通信が切断されている状況下でロボットは何もできなくなります。
プラントのある箇所に異常が発見されたと想定してみましょう。異常のある箇所に行き、そこで詳細な情報を収集し、原因究明し、その上で修理をし、報告をして仕事が完結します。この一連の行動が完結しないとどうなるか。人間がその工程に入り込んで何かをしなければならなくなります。人間が入らないといけないとなると、例えば福島原発のような現場だと結局、対応が迅速には進まなくなります。
ロボットの自律性に求められることは、センシングできるか否かというレベルに留まらず、自分で計画し、問題を発見し、将来を見通せるか否かのレベルまで拡大されています。こういったレベルの知能を考えていく必要があります。バーチャル・シミュレーションの世界では、そのレベルに達するのは難しくないかもしれません。ところがフィジカルの世界になると、人間が助けられない環境にロボットが置かれるシチュエーションを前提にしなければなりません。物理現象はロボットが人間の判断を仰ぐことを待ってくれないのです。待ってくれない物理現象に対してロボットが真摯に向き合って、それをきちんと適切にリアルタイムに処理をしていかなければならない。それができないとなると、自律とは言えないのです。
そう考えると、ロボットの自律化は難しいと言わざるを得ません。しかしながら、ユーザーが求めているのはそういうソリューションであり、フィジカル・インテリジェンスはそのソリューションを果たすことが究極の目的なのです。ユーザーは機材やロボットを求めていません。機材やロボットは必要悪であって、買わなくて済むなら買わない。高価な機械も、高度な技術もいらない。私たちはいつもそんなふうに言われるのです。そう言われても困ってしまうのですが、しかし、その通りと思います。災害空間を自律的に調査するロボットをつくる上で、そもそもロボットを導入するベネフィットは何なのかをしっかりと考えることが必要です。
人間をロボットで代替しようとするなら、人間と同等以上のベネフィットが求められるでしょう。それは必ずしも人間と同等以上の効率で仕事ができるということとは限りません。人間では入れない困難な場所に入れることもベネフィットと認められます。
ロボットの自律性と知能は、目的ではなく手段である。そのことを前提として、フィジカル・インテリジェンスを組み立てていく必要があります。災害空間ではバーチャル環境でのふるまいを生業としているAIは役に立たず、それを大きく超える範疇の機能を求められます。そこをしっかりと考えて手段をつくり出していかないといけないと思います。
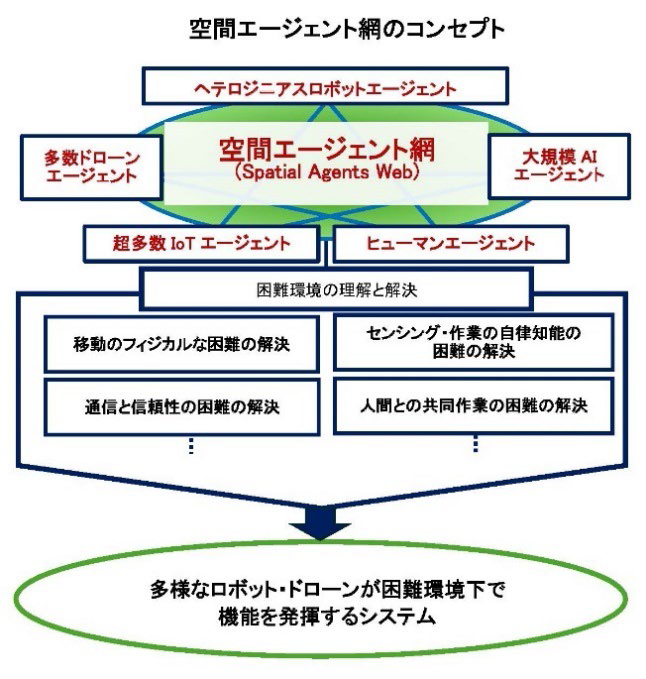
空間エージェント網のコンセプト
フィジカル・インテリジェンスを実現する一つの取り組みとして、“空間エージェント網”を推し進めようとしています。
“空間エージェント網”とは、物理的な空間、機能の空間、組織の空間、そういった様々な空間の中に多様な機能エージェントを配置して、各エージェントがお互いに通信し合い、協力し合うことによって目的を達成しようというものです。この時、エージェントとは、人間の代理として働くAI、あるいは環境や状況の理解に基づいて最適な行動を行う知能体と定義します。
目的は何か。それは困難環境を理解したり、そこで作業をしたり、それが可能なように環境を改変したりしようということです。
空間エージェント網で起こす知能のオープン・イノベーション
空間エージェント網研究コンソーシアムが組まれて空間エージェント網の構築への挑戦は既に始まっています。東北大学(代表機関)、情報通信研究機構、広島大学、筑波大学、制御システムセキュリティーセンター、大阪大学が参加して福島国際研究教育機構 (F-REI: エフレイ)の委託事業として災害現場など困難環境での活用が見込まれる強靱なロボット・ドローン技術の研究開発に取り組んでいます。
移動のフィジカルの困難の克服、通信の信頼性の困難の克服、センシング作業の自律性の困難の克服、人間との共同作業の困難を克服。このプロジェクトはそのような困難の克服の作業に挑みます。
そして多様なロボット・ドローンが連携し力を合わせて困難環境下で機能を発揮するシステムを構築していくことを目指します。
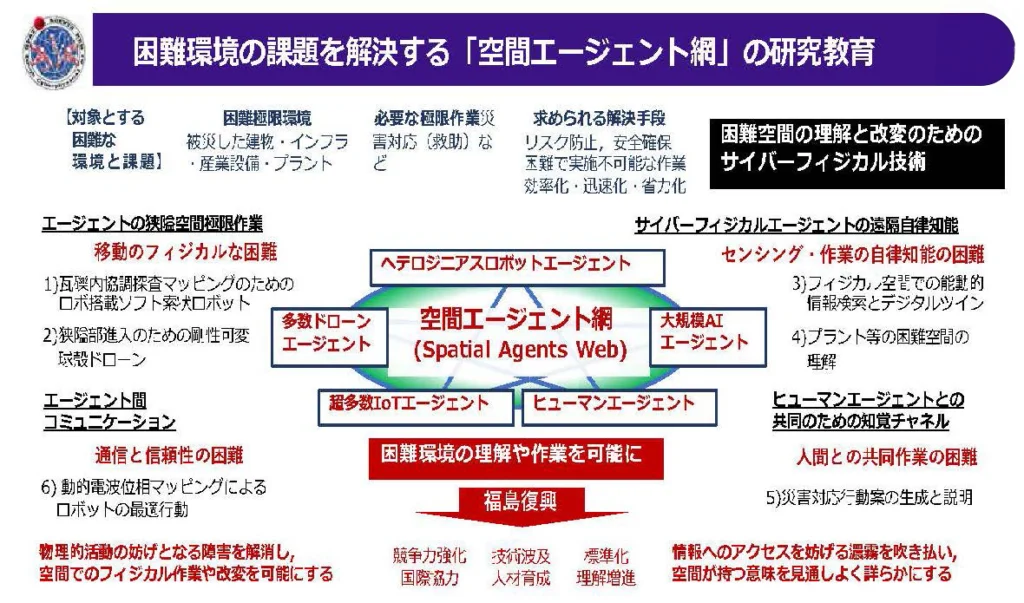
このような枠組みの中にさまざまなインテリジェンスを放り込んでいって、自由自在にそれらが繋がって協力できるような枠組みをつくることによって、知能のオープン・イノベーションを図ることができて、それがロボットの高度化に留まらず、空間の高度化に繋がっていくのではないかと考えています。
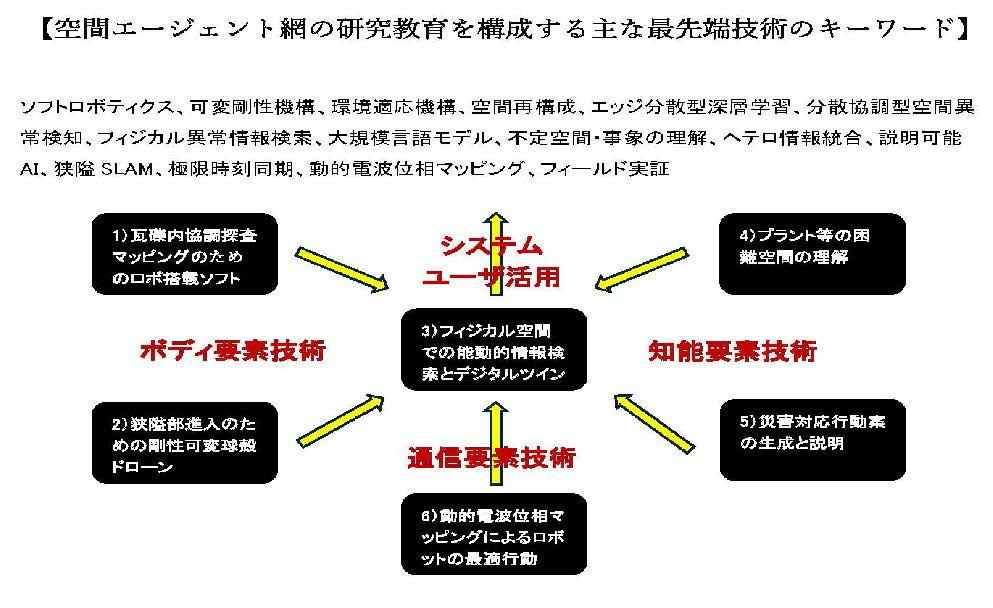
空間エージェント網が向かうべき方向性とオープン・イノベーションのイメージを掴んで頂くために以下の空間エージェント網の研究教育を構成する最先端技術のキーワードとそのシステムへの展開例を左図に示しました。
こちらの図からも、空間エージェント網が「人・ロボティクス・デジタルツインの共創」の場であることが、皆様も実感できるものと思います。
空間エージェント網が、これからさらにどんどんヘテロジニアスな知能を取り込みながら増殖し、知のオープン・イノベーションを起こし、困難環境を克服するタフネスを獲得していく。この挑戦をもって私のフィジカル・インテリジェンス(PI)の展開構想としたいと思います。
優等生ではなくタフなロボットづくりを目指して
2019年に東北大学タフ・サイバーフィジカル研究センターを発足させて5年経ちました。タフ・サイバーフィジカルという当研究センターが追求するコンセプトはAIロボットが社会課題を解決する役割を果たすための核になるものです。私たちは安定が保障された人工空間の環境下で気の利いた動きができる優等生ロボットではなくタフなロボットをつくりたいのです。ですから以下のようにタフネスを定義しました。
タフネスとは:実世界で稼働するAIは、無限定で様々な擾乱に晒された環境下で、サイバーフィジカルな“身体性”を以て実世界と関わる。また、“身体”の有限性から、取得できるデータ規模、定常性、品質などに制約を受けることになる。このような過酷な条件下で安定に高信頼で動作する柔軟性やロバスト性、そして広い適用性をタフと呼ぶ。
東北大学タフ・サイバーフィジカルAI研究センター

タフなサイバーフィジカルAIを実現したいという目的を共有して集う、フィジカルなロボットの開発者、AIの研究者、高速演算の専門家、サービスの専門家、産業界の研究者と事業開発者、自治体の方々と協力をしながら、さらに多彩な取組を進めていきます。この枠組みを活用して 空間エージェント網を高度化させて、困難環境でのタフネスを実現し、わが国の社会課題・産業課題の解決と国際競争力強化に貢献していく所存です。
出典:東北大学大学院工学研究科技術社会研究システム専攻/東北大学タフ・サイバーフィジカルAI研究センター(TCPAi)/株式会社現代経営技術研究所共同開催セミナー/第392回産業事情検討会(2024年6月18日開催)の田所諭氏報告からの再編集。
第1回 「レスキューロボットの社会実装挑戦史」はこちらからご覧下さい。
ロボットが災害現場で活躍する未来をつくる(全2回連載)第1回レスキューロボットの社会実装挑戦史

田所諭(たどころさとし)氏
東北大学タフ・サイバー・フィジカルAIセンター 特任教授。東北大学 大学院情報科学研究科 応用情報科学専攻 教授 東北大学タフ・サイバーフィジカルAI研究センター長を経て現職。1984年,東京大学工学系大学院修士課程修了。1993年,神戸大学助教授。2002年~,国際レスキューシステム研究機構会長。2005年~,東北大学教授。2014年,同副研究科長。2019年~,同タフ・サイバーフィジカルAI研究センター長。2014~18年,内閣府ImPACTタフ・ロボティクス・チャレンジプログラムマネージャー。2016~2017年,国際学会IEEE Robotics and Automation Society President。科学技術分野の文部科学大臣表彰科学技術賞他受賞。レスキューロボットの研究に従事。博士(工学).IEEE Fellow。